
Chenguang Xiao
Tensorboard is a great tool for machine leanring process visualization.
The key component of tensorboard is the SummaryWriter class.
The writer has methods include add_scalars, add_histogram, add_image, add_embedding, add_pr_curve, add_audio, add_text, add_video, add_mesh, and add_hparams.
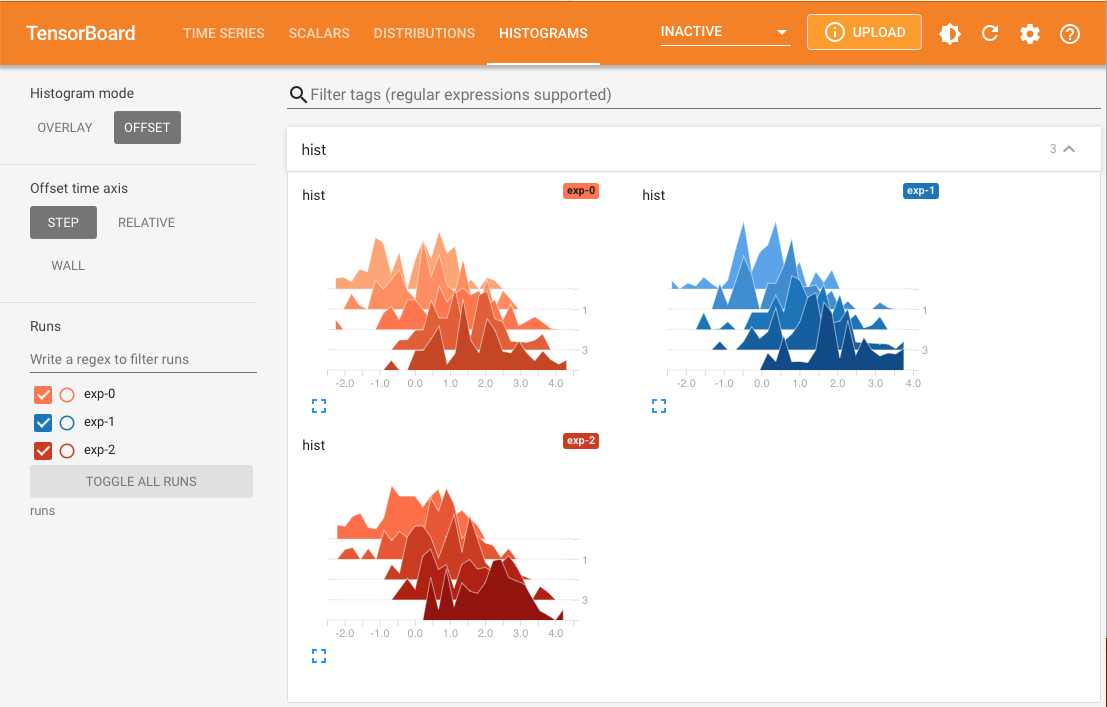
The most popular method is add_scalars, which can be used to plot loss and accuracy curves. As well as the add_histogram shown above.
After that, add_hparams is handy for hyperparameter tuning. In this post, I will show how to use tensorboard hparams to tune hyperparameters.
import numpy as np
from torch.utils.tensorboard import SummaryWriter
lod_dir = 'name_of_run'
epoch = 10
metrics = 'acc'
# instantiate summary writer, default directory is runs/
writer = SummaryWriter(log_dir=lod_dir)
# log the hyperparameters with metric to be compared
writer.add_hparams({'lr': 0.1}, {'acc': 0})
# log the metrics during training
for e in range(epoch):
writer.add_scalar('acc', np.sin(e/3), e)
This will results in the following tensorboard hparams.
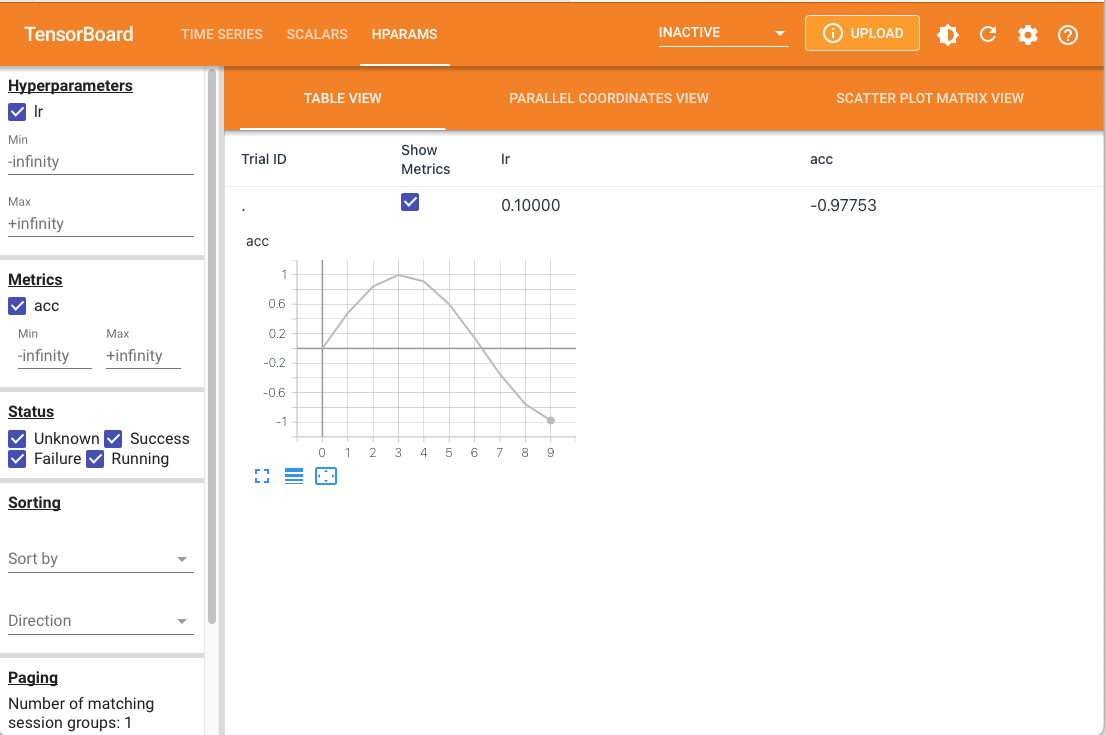
However, the torch build-in tensorboard hparams is not very user-friendly for two reasons.
- The hparams are loged into same file as other scalars in the same run.
- The hparams only log the metric once rather than during whole training process.
Thus, before running the code, make sure you made some modifications to the env_path/lib/python3.10/site-packages/torch/utils/tensorboard/writer.py file by commenting out the following lines.
# if not run_name:
# run_name = str(time.time())
# logdir = os.path.join(self._get_file_writer().get_logdir(), run_name)
# with SummaryWriter(log_dir=logdir) as w_hp:
# w_hp.file_writer.add_summary(exp)
# w_hp.file_writer.add_summary(ssi)
# w_hp.file_writer.add_summary(sei)
# for k, v in metric_dict.items():
# w_hp.add_scalar(k, v)
and add the following lines instead.
self.file_writer.add_summary(exp)
self.file_writer.add_summary(ssi)
self.file_writer.add_summary(sei)
Accessing the TB logs within python
There are times we need to access the TB logs within python.
For example, we want to plot the loss curve in the same figure as the accuracy curve.
To access single runs, we can use the EventAccumulator class.
from tensorboard.backend.event_processing.event_accumulator import EventAccumulator
# get single tb log as accumulator
log_dir = "path/to/log"
event_acc = EventAccumulator(log_dir).Reload()
# get tags in scalars
tags = event_acc.Tags()["scalars"]
# get loged scalars
scaler = event_acc.Scalars(tags[0])
# extract values from scalars
metric = [s.value for s in scaler]
To access multiple runs, we can use the EventAccumulator class with glob.
from glob import glob
# get multiple tb logs with glob
fds = glob("log/to/dirs")
events = [EventAccumulator(fd).Reload() for fd in fds]
Then every event in events is an EventAccumulator object, which can be accessed as previous demo.
After that, EventMultiplexer can load multiple runs recursively in a directory as well.
from tensorboard.backend.event_processing.event_multiplexer import EventMultiplexer
# get multiple tb logs with multiplexer
em = EventMultiplexer()
em.AddRunsFromDirectory("path/to/logs").Reload()
# get run and tag keys
runs = list(em.Runs().keys())
tags = em.Runs()[runs[0]]["scalars"]
# access scalars
scalars = em.Scalars(runs[0], tags[0])